Introduction
Let’s be honest—most of us built our first successful platforms the way everyone did in the 2010s: a big relational database, a monolithic app, and a pile of shared utilities humming quietly in the background. It worked—beautifully, even. Until it didn’t.
Back then, deployments were rare, regulators were quieter, and a change request didn’t feel like prepping for a moon landing. Fast forward to today, and that same simplicity has become our Achilles’ heel. A tiny bug fix? It requires a full redeploy. One team’s schema change? It breaks another’s feature without warning. And those shared tables? They’ve turned collaboration into a minefield. You tweak something for one product line, and suddenly three others are calling you in a panic. Sound familiar?
Some folks thought the answer was just to break things apart—slap a “micro-service” label on a few APIs and call it a day. But when everything is still synchronous, and no one really owns the data, you end up with a distributed mess. Calls fail. Systems spiral. No one knows which version of truth to believe. We’ve all seen those “micro-service” setups where just looking at a dashboard makes you nervous.
But here’s the good news: there’s a better way—and it’s not a mystery anymore. Over the past years, a repeatable path has emerged. It doesn’t start with tools or technology. It starts with rediscovering your business through Domain-Driven Design (DDD). You map what your business really does, define shared language that actually makes sense to everyone, and carve out boundaries that reflect real accountability.
Then, once you’ve drawn those lines, you connect them—not with brittle APIs—but with durable, auditable, immutable events. Think Kafka, Pulsar, or whatever log-based system fits your environment. You phase things out using strangler patterns, keep data consistent with outbox strategies and sagas, and you test contracts—not just features—so that change becomes something your teams don’t dread.
This playbook walks you through all of it, chapter by chapter. No vendor fluff, no motivational quotes—just practical, field-tested advice. Here’s what we’ll unpack together:
- Why starting with DDD matters right now—not six months from now.
- How to understand what you’ve already built, technically and organizationally.
- How to map your domains and align your teams to them.
- How to design an event model that won’t collapse under change.
- How to select the right infrastructure backbone—and avoid surprises.
- How to actually carve out services from a monolith safely.
- How to guarantee resilience when things go sideways (because they will).
- How to test, trace, and govern what you build—without slowing delivery.
- How to upskill your teams and navigate the human side of all this.
- And finally, how to avoid the most common traps we’ve all fallen into.
If you follow the guidance, by the middle of the year you could already have one bounded context running independently, emitting auditable events, and—get this—delivering change without fear.
Let’s get started.
What’s the Rush?
If you’re wondering why there’s such urgency around modernising software architecture lately, it’s not just a passing trend—it’s real pressure, coming from all sides. Regulators, competitors, and even your own finance department are turning up the heat. And if your systems are still monolithic, that heat feels like it’s boiling the whole pot.
Let’s talk about regulation for a second. In March 2024, the EU Parliament passed the Artificial Intelligence Act, and by May it was locked into law. That’s not a distant threat—it’s here. If your platform includes any “high-risk” AI components, you’re now legally on the hook for proving things like data origin, audit trails, and post-deployment monitoring. That’s a tall order for a monolith with shared data layers and spaghetti code. It’s almost laughable to imagine generating a reliable audit trail when you can’t even separate logs by team or feature. Deployments bundled into multi-hour windows? They bury any chance of traceability. Good luck meeting transparency standards when everything’s lumped together.
And regulation isn’t your only fire. Let’s pivot to performance. The 2024 DORA State of DevOps report drew a hard line between winners and laggards. The elite teams? They deploy several times a day and recover from outages in under an hour. The rest? Monthly deploys and multi-day outages. That gap doesn’t just show up in engineering metrics—it hits revenue. Fast movers test, ship, and iterate faster than traditional shops can even scope a feature. Their speed isn’t luxury—it’s competitive edge.
Now mix in a financial squeeze. After a string of interest rate hikes, the money men and women are asking tougher questions. “Why is our cloud bill still climbing?” According to Everest Group, average overspend sits north of 10%. In the UK alone, one study pinned delays and deployment drag at more than £100,000 per company. Not a rounding error.
This trio—legal scrutiny, operational expectation, and financial discipline—makes clinging to a monolith a dangerous game. You’re either agile and auditable, or you’re struggling and exposed.
So What Does a DDD-First, Event-Driven Architecture Actually Give You?
It gives you air to breathe.
Here’s the short list—but make no mistake, these benefits aren’t isolated. They stack. They multiply.
- Autonomous teams: Each one owns its context—its code, its data, its release timeline. No more waiting for an ops window or tiptoeing around a central DB.
- Compliance by construction: Events are immutable, timestamped, and self-describing. They aren’t just useful—they’re legally defensible.
- Scalability with intent: Need to ramp up fraud scoring without touching checkout logic? No problem. Scale what matters, when it matters.
- Focused innovation: A team working on a new feature in one context doesn’t need five sign-offs from risk management, operations, and legacy platform leads. That isolation is freedom.
And the ripple effects? Fewer meetings, tighter sprints, fewer late-night incident calls, and—this is a big one—the confidence to move fast even when the rules get stricter.
Taking Stock of the Current Landscape
You Can’t Change What You Don’t Understand
Here’s something we’ve all seen: a team dives into migration without truly grasping what they’ve built—or inherited. Then, halfway through, the project stalls because of “unexpected dependencies” or “surprise compliance blockers.” Sound familiar?
Truth is, every failed migration has one thing in common: it underestimated the mess. That’s why the first real move in this journey isn’t coding—it’s seeing.
Start with Business Capabilities, Not Code
Engineers love to open an IDE and trace function calls. But that’s the wrong door to walk through first.
Instead, start with your product managers. Ask them for a full list of your business capabilities—the stuff that actually earns you money or supports someone who does. Things like: checkout, recommendations, user profiles, fraud scoring.
Then attach meaningful data to each capability:
- How much revenue does it drive?
- How often does it change?
- Is it subject to regulatory scrutiny?
Now make that list visual. Use a Miro board or mural canvas and create a heatmap. The visual feedback is immediate. Suddenly, the high-value, high-risk zones pop out. These are your pressure points—and likely candidates for early refactoring.
Then, Map Out Technical Coupling
Once you know what your business cares about, it’s time to trace what’s really tangled underneath.
Fire up your static analysis tools and look for:
- Shared libraries: How tightly are modules bound at compile time?
- Database joins: Are multiple modules touching the same tables?
- Runtime calls: Who’s calling whom synchronously?
Service mesh telemetry or APM tools like New Relic and Dynatrace can help you expose these runtime dependencies.
You’ll end up with a spaghetti graph. That’s okay—it’s supposed to be ugly. Look for dense clusters. These are your danger zones. Ironically, they’re often the worst places to start breaking things apart. Why? Because complexity breeds paralysis. Instead, choose a capability with clean boundaries and visible business value. Your future success story needs to resonate.
Now, Overlay the Org Chart (Yes, Really)
Here’s the thing: Conway’s Law isn’t a law because someone said so—it’s a law because it happens whether you like it or not.
Whatever your org chart looks like, your software will mirror it. So take your coupling graph and sketch team boundaries on top. Watch what happens:
- If one team owns a module but has to reach across five services to get work done, that’s a cognitive sinkhole.
- If three teams constantly edit the same folder in the monolith, you’re looking at a domain that’s screaming for clarification.
In both cases, it’s time to think DDD. And if your engineering org is surprised by how misaligned things are? Even better. That’s exactly what this visibility is for.
Don’t Forget Regulation—It’s Not Optional
Let’s not kid ourselves—PCI DSS 4.0, EU AI Act, SEC incident reporting—they all have data classification requirements baked in. That means certain columns, tables, or message fields are legally sensitive. You can’t just copy them somewhere else and hope no one notices.
So tag your sensitive data:
- Cardholder data
- Personally identifiable info
- Anything tied to high-risk AI inputs
This matters for two reasons:
- It tells you where you can’t afford to be sloppy during migration.
- It helps you plan what to migrate first—and what must wait until you’ve got the proper guardrails in place.
If you ignore this part? Expect to rewrite your migration roadmap when legal sends you a frantic Slack message two days before go-live.
Carving Bounded Contexts
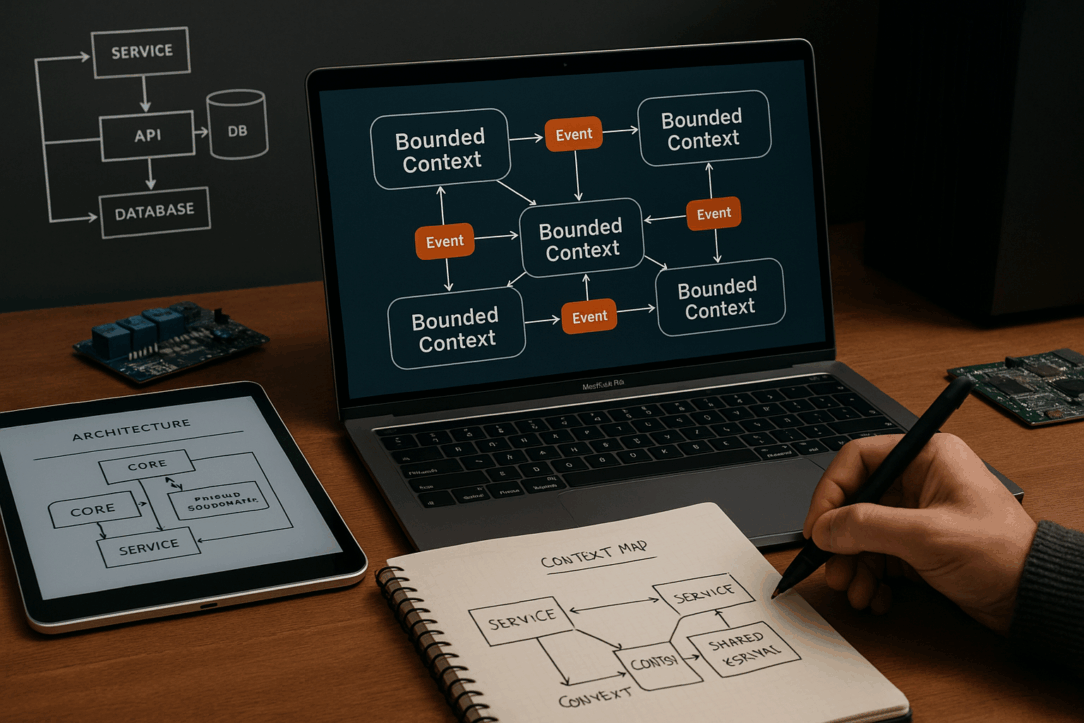
So… What Even Is a Bounded Context?
Here’s the thing: every large system is already split into domains—it’s just that nobody’s named them, nobody owns them, and half of them are overlapping. That’s where things get messy.
A bounded context isn’t just a fancy term from Eric Evans’ playbook. It’s a boundary—both linguistic and technical—that says: “This is our language, our model, our data. Outside of it? Not our problem.” Once you start thinking in contexts, you stop solving for generic abstractions and start aligning to actual business flows.
But you can’t define bounded contexts in a vacuum. You need stories.
Lock the Right People in a Room and Tell Stories
Seriously. Get ten people in a room: a product owner, a senior engineer, a tester, someone from ops, and your favorite data analyst. Then ask one deceptively simple question:
“When a customer places an order, what happens next?”
What happens is magic. People start talking. You’ll see whiteboards fill with actors, arrows, and notes: “Authorize Payment,” “Reserve Stock,” “Generate Invoice.” Everyone starts sketching the flow they live and breathe.
Color-code the steps. Mark ownership. You’ll notice patterns forming—terms like Order, Payment, Shipment—used repeatedly and consistently.
That shared vocabulary? That’s your ubiquitous language. Once it’s validated, it’s more than just words. It’s the blueprint for your system’s shape.
Draw the Map. Literally.
Take everything from the workshop and turn it into a context map.
Draw circles:
- Core domains that differentiate your business
- Supporting domains you still need, but don’t define you
- Generic domains like identity, notifications, or file storage
Then connect the dots—literally. Use arrows to mark which domains depend on others. It’s not just academic; it’s strategic. Upstream domains influence, downstream ones depend. That matters when you’re sequencing your work.
Here’s the kicker: align this map with your org chart. Each bounded context should have an owning team. Clear KPIs, a deploy pipeline, the works.
If two contexts fall under the same team, maybe they belong together. If a team claims three wildly different contexts? Push back. It’s too much. Negotiate a split. The map is your contract. Treat it that way.
Anti-Patterns Lurking in the Shadows
Now, a warning. There are landmines here. Let’s call them out:
- Micro-service per aggregate: It sounds clean. It isn’t. Turning every root entity into its own service leads to noisy networks and awkward conversations with ops when latency triples.
- Technical slicing: Splitting by layers—API, logic, data—creates half-baked services that depend on each other like co-dependent roommates. Don’t do it.
- Ignoring Conway’s Law: If your “context” spans four teams, it’s not a context—it’s an on-call nightmare waiting to happen.
Here’s a quick reality check: take three incidents from the past year. Ask, “Could the owning team have resolved this on their own?” If the answer is “No,” redraw the boundary.
You’re not just building micro-services. You’re building accountable units of delivery. That’s what a bounded context is. And when you get it right? Everything—from deploys to bug fixes—starts to feel a little lighter.
Designing a Durable Event Model
Events Aren’t Just Payloads. They’re Commitments.
Once you’ve defined your bounded contexts, you need a way for them to talk to each other—without yelling across the room.
That’s where events come in.
But hold up—this isn’t just about slapping messages onto a queue. An event isn’t an afterthought or a byproduct. It’s a business fact, frozen in time. And if you treat events that way—from day one—you’ll spare yourself a lot of pain down the road.
Domain Events vs. Integration Events: Yes, There’s a Difference
Let’s clear this up right away.
- A domain event is a pure expression of what just happened. “Payment Authorized.” “Order Cancelled.” It’s born inside a bounded context, owns its truth, and never changes once published.
- An integration event is a translation—sometimes filtered, sometimes enriched. Maybe it redacts personal data, maybe it adds some fluff for analytics. That’s fine—but don’t confuse the two.
Why does this matter? Because if your “Shipping” service starts treating a cleaned-up analytics event from “Payments” as the gospel truth, you’ve just introduced brittle coupling in disguise.
Naming Events: It’s Not Just Semantics
Event names matter. They’re not just for logs or dashboards—they’re part of your ubiquitous language. So treat them with care.
- Use past tense:
order.shipped.v1, notorder.ship. - Be explicit about intent. “UserRegistered” tells you something meaningful. “UserUpdated”? Not so much—what was updated? Why?
- Include a version suffix right in the name. It’s not overhead—it’s a signal. When breaking changes come (and they will), they come in cleanly as
.v2, not silently through unexpected field removals.
And yes—never remove a required field. Add optional ones. Mark things as deprecated. But never yank something out from under consumers. You’re not just publishing events—you’re making contracts.
Picking the Right Schema Technology: Don’t Default to JSON
Let’s talk tech for a second.
JSON is easy. Everyone can read it. It’s human-friendly… until it isn’t.
JSON doesn’t enforce contracts. You won’t know something broke until a consumer quietly fails in production. Then you’re back in Slack trying to piece together what went wrong, which schema changed, and who forgot to update what.
Tools like Avro or Protobuf solve this. They compress well, support evolution rules, and work great with schema registries like Confluent or Apicurio. These registries act like the bouncers outside your event bus. If a new schema breaks backward compatibility, the pipeline halts. Good. Let it halt.
You’d rather fix a schema in CI than roll back a broken event in prod.
Choreography vs. Orchestration: Know When to Let the Band Play
You’ve got your events. You’ve got your services. Now, how do they dance?
- For simple, linear flows—like order placed → payment authorized → order fulfilled—event choreography works great. Each service listens, reacts, and emits.
- But what about complex, reversible flows? Say you booked a shipment, but the warehouse fails to confirm. Now you have to roll back the charge, cancel the label, and notify the user.
That’s where orchestration comes in. A dedicated process manager runs the show—tracking state, handling retries, and issuing compensating actions. Yes, it introduces a bit of indirection. But it also saves you from days of outage triage when something goes wrong halfway through a ten-step process.
Use both patterns. Pick based on context. But above all, design for clarity.
Choosing the Event Backbone and Supporting Infrastructure
Your Events Deserve More Than a Message Queue
Once you’ve nailed down your event model, the next question is: where do those events actually live? And how do they move? If you get this part wrong, it won’t matter how clean your context map is—your services will be arguing over garbled messages or tripping over race conditions.
Let’s get one thing straight: this is about logs, not mailboxes.
Traditional queues (like RabbitMQ or SQS) are fine for fire-and-forget tasks, but building an event-driven system requires more than pushing bytes around. You need persistence. Replayability. Individual consumption offsets. In other words, you need a durable event log.
Kafka, Pulsar, or the Cloud Buffet?
Apache Kafka became the default choice for a reason. It gives you an ordered, append-only log where each consumer tracks its own progress. So your real-time fraud detector doesn’t get slowed down by some nightly batch job.
Apache Pulsar brings some advantages Kafka lacks—like multi-tenancy out of the box and tiered storage for archiving older events without clogging up your hot path. Depending on your scale and use case, it might be the right pick.
Don’t want to manage clusters? Totally fair. Cloud options like Google Pub/Sub, AWS MSK, or Azure Event Hubs abstract the infrastructure away—but watch out. You’ll trade off some fine-grained control, so understand what you’re giving up before going all-in.
When you evaluate, ask:
- Do we need strict ordering for sagas or financial transactions?
- Do we care about exactly-once semantics? (Spoiler: most teams settle for at-least-once + idempotency.)
- What’s our latency tolerance—especially if we’re bridging between cloud and on-prem?
Schema Registry and Contract Testing: Your CI/CD’s Best Friend
If the event backbone is the nervous system, then the schema registry is the immune system. It prevents corrupted or incompatible events from entering the bloodstream.
Here’s how it works:
- A developer updates an event schema.
- The new version is pushed to the registry.
- Compatibility checks run—both forward and backward.
- If it passes, it gets published. If it fails, it stops cold.
Think of it like type-checking your entire event model—before deployment.
Run contract tests in your CI pipeline to ensure no one breaks a downstream consumer without knowing it. That simple step has saved countless hours of post-deploy panic.
Some popular choices:
- Confluent Schema Registry (Kafka-native)
- Apicurio
- Open-source Kafka-compatible options
Trust me, once you’ve caught a bad schema in CI, you’ll wonder how you ever lived without it.
Observability: Don’t Fly Blind
Events are invisible unless you make them visible.
Here’s what you want:
- Use OpenTelemetry traces to stitch together end-to-end flows—linking REST calls to Kafka offsets and back.
- Treat every event as both a metric and a trace. Count them. Time them. Plot them.
- Watch for lag—that’s your canary. If a consumer falls behind, that’s not just a tech issue; it could mean orders aren’t shipping, payments aren’t processing, users are churning.
Your observability stack should surface:
- Events produced per minute
- Consumer group lag
- Time from publish to consumer acknowledgment
Without this visibility? You’re just hoping everything works. And hope is not a strategy.
Security and Compliance: Bake It In
Compliance can’t be bolted on later. Build it in now, or pay for it tenfold later.
Some essentials:
- TLS everywhere. Encrypt traffic in flight. No excuses.
- Access control lists (ACLs) so only the owning service can write to its topic.
- Tokenization or encryption for sensitive fields—think card numbers, email addresses, anything PII.
If a downstream consumer doesn’t need the raw data, don’t give it to them. Use integration events with redacted payloads.
Not only does this keep you on the right side of GDPR, but it also positions you well for newer regulations like the AI Act, which demands explainability and transparency. Immutable events with tight access and audit trails? That’s compliance gold.
Migration Strategies in Depth
You Can’t Rewrite the Plane Mid-Flight—But You Can Reroute It
By now, you’ve probably realized: you’re not starting from scratch. There’s a monolith. It’s working—sort of. It’s got warts, sure, but it’s also paying the bills. You can’t just flip a switch and replace it with shiny micro-services. That’s a fantasy.
What you need is a strategy that lets you move incrementally, safely, and without breaking everything every other Tuesday.
Let’s talk tactics.
The Strangler Fig: Nature’s Guide to Legacy Decomposition
Martin Fowler coined the term, but nature got there first. The strangler fig grows around a host tree—bit by bit—until one day, it stands alone.
Here’s how it works in code:
- You place a thin facade—say, an HTTP proxy or routing rule—between clients and your monolith.
- You build new functionality as micro-services.
- That facade selectively routes calls: new stuff goes to the service; old stuff stays with the monolith.
- Over time, more traffic shifts to the service.
- Eventually, the monolith’s old module becomes redundant—and gets deleted.
Zero downtime. No big-bang rewrites. Just quiet, steady progress.
The Outbox Pattern: Say It Once, Say It Right
Here’s the problem with event-driven systems: what happens if the service updates the database but crashes before publishing the event?
Boom. You’ve got data that no one else knows about. Silent inconsistencies. The kind that haunt you at 3 a.m.
Enter the Outbox Pattern.
Instead of publishing events directly, you:
- Write the event to a dedicated outbox table, in the same database transaction as your business logic.
- A separate relay process reads from the outbox and publishes to Kafka (or whatever broker you’re using).
Now, even if the relay crashes, the event is safely stored. No duplicates. No ghost updates.
This is your foundation for exactly-once semantics—or at least effectively once, which is what matters most.
CDC: When You Can’t Touch the Monolith
Sometimes you’re stuck. The monolith’s ORM is older than your intern. The team that built it is long gone. You can’t risk changing anything inside.
That’s when Change-Data-Capture (CDC) becomes your secret weapon.
Tools like Debezium hook into the WAL (Write-Ahead Log) of your database. They listen for row-level changes and stream them out as events—without touching your application code.
It’s a clever workaround, but there’s a catch: CDC gives you technical changes, not business intent.
So, a row changes. Great. But what does it mean? Was the order cancelled? Was it just an address update? You’ll need a transformer layer to map those raw changes into proper domain events.
Still, when the monolith is off-limits, CDC is the way in.
Managing the Two Truths Problem
During migration, you’re in a messy state: some data lives in the monolith; some in your shiny new service. So how do you keep your story straight?
Here are your main options:
- Immutable ownership: Only the owning context writes to a table. Others consume it as a read-only projection. No overlaps. No debates.
- Temporal fences: The new service handles all future data—new users, new orders, etc. The monolith keeps the historical stuff. You just draw a date line and stick to it.
- Graceful rollback: Always have a way back. Keep feature toggles that let you reroute traffic to the monolith if something goes sideways. The new service doesn’t get deleted—it just goes dark until you fix it.
Real talk: teams that practice rollback drills recover 10x faster than those that rely on duct tape and heroic last-minute debugging.
Ensuring Consistency and Resilience
Your System Will Fail. Now Design Like You Know That
Distributed systems aren’t gentle. Messages get dropped. Services restart mid-transaction. Someone restarts a Kafka broker without telling the team. It happens.
So the real question isn’t “How do we prevent failure?” It’s “How do we survive it—and stay consistent while we’re at it?”
This is where patterns like sagas, idempotency, and even a little chaos engineering come into play.
Sagas: The Narrative Backbone of Distributed Consistency
When a process stretches across multiple services—say, placing an order, charging a card, booking shipment, and confirming delivery—you can’t just wrap that in a traditional transaction. There’s no cross-service BEGIN/COMMIT in this world.
What you need is a saga.
Sagas are long-running, distributed workflows built from smaller, isolated transactions. Each step completes and emits an event. If a step fails, the saga kicks off compensating actions—think: refund the payment, restock the item, notify the user.
Two ways to manage this:
- Choreography: Each service listens for specific events and emits follow-ups. Light, elegant, but a little opaque once things get hairy.
- Orchestration: A process manager tracks the whole flow explicitly—logging state, making decisions, and coordinating retries. Slightly heavier, but far more visible.
Whichever you choose, persist the saga’s state. Otherwise, if the coordinator goes down mid-flight, you’ve got no recovery plan—and no trace of what was mid-air.
And make sure compensating actions also emit events. You’ll want to trace these steps later when something breaks and the postmortem starts.
Idempotency: Your Safety Net Against “Oops, It Happened Twice”
Here’s a law of distributed systems: If something can happen more than once, it will.
Network blips. Broker retries. Misconfigured consumers. You’ll get duplicate events. It’s not a bug—it’s a guarantee.
That’s why idempotency is your best friend.
Each event needs:
- A unique event ID
- A natural aggregate ID (like order number or payment ID)
When your service consumes an event, it checks: “Have I seen this before?” If yes, skip. If no, process and log the ID.
No complicated deduplication logic. No weird partial state. Just a clean record of what’s been handled.
Avoid relying on random UUIDs alone—they’re hard to trace and even harder to debug. Lean on domain-specific keys whenever you can.
Chaos Engineering: If You Don’t Test Failure, It’ll Surprise You Later
Want to know if your system can handle failure? Don’t wait for prod to find out.
Instead, run controlled chaos:
- Delay messages randomly.
- Drop 5% of events at random.
- Restart brokers mid-test.
- Inject partition unavailability.
- Simulate a replay storm during peak hours.
Your goal isn’t to break things for fun—it’s to build muscle memory:
- Do your consumers retry with exponential backoff?
- Does the dead-letter queue catch and alert on poisoned messages?
- Can you replay lost events without corrupting state?
Make these drills a habit:
- Run chaos scenarios in staging every sprint.
- Do production game days once a quarter.
The teams that rehearse failure recover faster—and with fewer grey hairs.
Testing, Tracing, and Metrics
“It Works on My Machine” Doesn’t Cut It Anymore
When you move to an event-driven architecture, something shifts. You’re no longer just testing APIs—you’re testing conversations. And like any good conversation, what matters isn’t just what’s said, but when and how it’s said.
That means your test suite needs an upgrade. And your observability stack? It becomes a lifeline.
Let’s break it down.
Contract-Driven Testing: Trust, But Verify
In a world where services communicate through events, schemas are contracts. And contracts aren’t optional. If a producer makes a change, consumers need to know before it hits production.
So how do you keep everyone honest?
- The producer team maintains event schema files in their codebase.
- The consumer teams pull those schemas into their test suites using stub generators.
- On every CI run, the system checks: is the change backward-compatible?
For example:
- If a producer adds a new field? Cool—just make it optional.
- If they remove or rename a required field? CI should fail. Hard.
No silent breakage. No weekend firefights. Just clean, predictable communication.
And yes—make this a ritual, not a recommendation. If a pull request modifies a schema, it must include:
- Compatibility results
- Updated contract stubs
- Migration notes for consumers
Automate it all. Humans forget. Pipelines don’t.
End-to-End Replay: Your Secret Weapon Against Edge Cases
Let’s face it—unit tests miss things. Integration tests get close, but they’re still limited. You know what catches the weird bugs? Replaying real-world events.
Here’s how to build your replay harness:
- Capture a slice of production traffic (sanitized if needed).
- Store it in a separate log or object store.
- On every release candidate, replay those events into a staging environment.
- Compare actual outcomes to expected state or traces.
This isn’t just testing—it’s simulation. You’ll uncover:
- Events arriving in unexpected orders
- Edge cases you didn’t even know existed
- Latency-induced flakiness
Bonus: the replay harness becomes a living spec. Every new corner case you discover? Add it to the next run.
The Golden Signals of Event-Driven Systems
Traditional apps have RED metrics: Rate, Errors, Duration. That’s a good start—but event-driven systems need more.
Here’s what to track:
- Event throughput: How many events are being produced and consumed per minute?
- Consumer lag: Is any service falling behind? Lag is the canary in your coal mine.
- Mean processing latency: How long does it take from event publish to final acknowledgment?
- Saga failure rate: Are distributed workflows completing, compensating, or falling flat?
Now bring these metrics into business focus. Tie them to real KPIs:
- A five-second delay in
order.fraud_check? That might correlate with cart abandonment. - A spike in
payment.refund_failedevents? That’s a support nightmare in the making.
Visualize all of this in Grafana, Datadog, or whatever dashboard you live in. Don’t just throw alerts over the wall—make them actionable.
Governance and Change Management
It’s Not Just the Architecture That Changes—It’s the Culture
Here’s a not-so-secret truth: most migrations don’t fail because the tech is wrong. They fail because people weren’t aligned, weren’t prepared, or weren’t heard.
Governance isn’t about bureaucracy. Done right, it’s about reducing surprises, building trust, and making change feel safe. And when the foundation is events and bounded contexts, governance becomes something you bake into your pipelines—not just paste on at the end.
Let’s look at the rituals that make change stick.
Publishing Policy: One Team, One Topic
This is the golden rule. Repeat it. Tattoo it. Whisper it into your schema registry at night:
One team owns each topic. Period.
They—and only they—decide what goes into that schema, how it evolves, and when it changes. Cross-team consumers? Welcome, but they’re guests, not co-authors.
That means every pull request touching an event schema must include:
- A registry compatibility pass
- Updated contract stubs for any affected consumers
- Migration notes in plain language
Set up automated checks in GitHub or GitLab. Don’t rely on engineers to remember every step. Let your CI yell if someone breaks the rules. It’s better than Slack yelling after prod breaks.
This isn’t control for control’s sake—it’s protection against accidental coupling and silent regressions.
Documentation Cadence: Keep the “Why” Alive
People come and go. Teams change. Six months from now, someone will ask, “Why does this topic even exist?” or “Why do we version that event instead of extending it?”
That’s where Architecture Decision Records (ADRs) come in.
Every schema change, boundary adjustment, or integration handshake should come with an ADR. Just a short doc that says:
- What changed
- Why it changed
- Who decided
- And when
Use a bot to post new ADRs in your team’s #architecture Slack channel. Once a quarter, clean up the old stuff. Keep your decision log readable—because it’s not just documentation. It’s your project memory.
People First: Training Is Not Optional
Most migration blockers aren’t technical—they’re human. People don’t like uncertainty, especially when their day-to-day changes.
So invest—early and often—in skills, language, and practice.
Here’s what actually works:
- Event-storming workshops: Run by external coaches or experienced facilitators. They help teams discover domain boundaries together and define ubiquitous language without arguing about data models first.
- Kata exercises: Tiny, low-risk practice sessions where devs build outbox-driven services from scratch, break them, and fix them—in a sandbox where failure is safe.
- Shared vocabulary cheat sheets: Yes, like flashcards. So that testers, analysts, and devs all use the same nouns. It sounds small. It’s not. It’s alignment made visible.
These don’t cost much. Less than a week of downtime, for sure. But they build something far more valuable than code: confidence.
And when people feel confident in the platform and in each other, things ship faster. Reviews go smoother. Escalations vanish. Your migration becomes a shared achievement—not a top-down mandate.
Common Pitfalls
The Mistakes Everyone Makes (So You Don’t Have To)
You’re almost there. You’ve got your bounded contexts, your event model, your migration strategy, and your team on board. But let’s slow down for a moment—because even with the best intentions, things can go sideways.
Let’s walk through the usual suspects. Some are technical. Some are cultural. All are avoidable.
Pitfall #1: Event Spaghetti
You know those generic “updated” events? Like user.updated, product.changed, something.happened?
Yeah—don’t do that.
They sound flexible, but in practice they become dumping grounds for vague changes. Consumers can’t reason about them. Schemas balloon. Debugging becomes guesswork.
Instead, use explicit, domain-namespaced events. order.shipped.v1. user.email_changed.v1. You’re not just naming messages—you’re designing interfaces.
Clarity is power.
Pitfall #2: Overeager Slicing
We get it. You’re excited. The strangler worked once, and now you want to slice everything. But slow down.
Not every module needs to be a micro-service right away. Resist the urge to turn every aggregate or table into its own bounded context.
Start with one core domain. Prove it works. Learn from it. Then expand. Teams that migrate in waves succeed more often than those that try to “fix everything” in one roadmap cycle.
Pitfall #3: Zombie Contracts
Old event versions pile up. No one uses order.created.v1 anymore, but it’s still in the registry—just sitting there, waiting to confuse a new hire or trigger a bad deploy.
Solution? Quarterly registry pruning. Track consumer usage. Delete unused schemas with ceremony. Celebrate it. Dead contracts are technical debt in disguise.
Pitfall #4: Telemetry Sticker Shock
If you trace every event, log every payload, and monitor every span at 100% fidelity—your observability bill is going to look like a joke.
So be smart:
- Sample traces during normal traffic
- Compress logs before they hit storage
- Archive cold events to object storage (e.g., S3, Azure Blob) after a week
You don’t need everything, forever. You need just enough, at the right fidelity, for the right audience.
Pitfall #5: Unfunded Skill Gaps
This one’s subtle. You’ve planned the tech. You’ve drafted the migration board. But you forgot to budget for people.
Event-driven architecture isn’t just a new stack—it’s a new mindset. If your engineers have never done DDD, never written a consumer that handles retries gracefully, never worked with schema evolution, you can’t assume they’ll just “figure it out.”
So:
- Make training part of the plan
- Track DDD fluency like you track sprint velocity
- Even bring in external coaches for a few sessions
Think of it this way: the cost of training is a rounding error compared to the cost of a failed migration.
Conclusion: No, You’re Not Just Refactoring
Let’s not sugarcoat it—breaking a monolith is hard. It’s not about code alone. It’s about reshaping how your organization thinks, speaks, and builds software.
But here’s the thing: it’s possible. And more than that, it’s necessary.
Domain-Driven Design gives you the compass. It helps you see the real business logic hiding in the mess of code. Event-driven architecture gives you the roadways—resilient, decoupled, scalable. Together, they let you build something that grows with your business, not against it.
Start by seeing your domain clearly.
- Draw your bounded contexts.
- Give each team a clear identity.
- Let events tell the story of what matters.
Choose an event backbone that fits your latency and governance needs. Use outboxes and CDC to migrate carefully. Build sagas to orchestrate change. Keep your systems honest with contract tests and tracing.
Measure what matters. Teach what’s missing. Move piece by piece. And never let the fear of complexity freeze you in place.
Because the alternative? That monolith you’ve been nursing for a decade? It’s not just slowing you down—it’s draining your team’s energy, your customer’s patience, and your ability to adapt.
Act now, and in a year, you’ll look back and wonder why “big-bang rewrite” ever seemed like the only option.